1 Why bother?
Starting a PhD is a bit like falling into the deep ocean. You better learn how to swim as fast as possible, you will get a lot of salty feedback, and you should try to avoid any predators by all means. The good news is that there are many awesome people out there who will help you to stay on top (or at least help you not to drown). Taking their advice, I have managed to build a method that allows me to sail smoothly on the deep waters of a submission procedure.
Despite a lot of critique, I actually like the peer-review process. But for it to be helpful, reviewers need access to all files and the raw code that was used for a manuscript. Only then they will be able to tell if the results of the manuscript are reliable or not. Even worse, the code and the data should be in an analysis ready format, so that the reviewers don’t have to wrangle with e.g. absolute directories. Journals will often give you the opportunity to submit some code files along the manuscript, but this will definitely destroy your neat project structure and reviewers will stop to look at your code after some frustrating minutes.
Using Rstudio’s project option, github, and figshare, I have managed a way to provide all of my code and data anonymously and in an analysis ready structure for reviewers. I feel save knowing that reviewers have access to all files but no one else has, reviewers will have an easy time reproducing my results, and editors will have more confidence in the reliability of my manuscript.
2 The basic set up
I always start with a R project on my local computer. It really helps to set up a clean project structure with folders for raw data, results, and so on. The Chapter 8 of the R for data science introduces some basic concepts of projects. The following image shows a R project for a current manuscript.
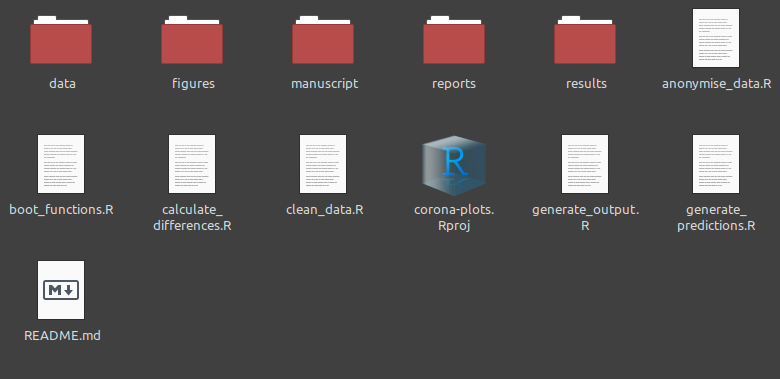
Fig. 1: Examplary project structure
Note that I have a README text file there, stating what each code-file is doing, where to find data, and so on. It is basically a tutorial for everyone working with the project on how to sucessfully work with it.
Remember to navigate between the folders (e.g. when reading in data or when exporting plots) with the awesome here package. This will help the reviewers later on to easily reproduce your results without the need to change any code or directories.
After setting up the infrastructure, and before working on any code, I set my project under version control using github. I will not cover why you should use a version control tool while doing data science, but I strongly recommend it for everything you do. And you will need github for disclosing code and data anyways. Remember to set the repository on private, so no one else can access (or steal) your code before publication. Upon acceptance, you can change the repo to public and everyone can look at your awesome code.
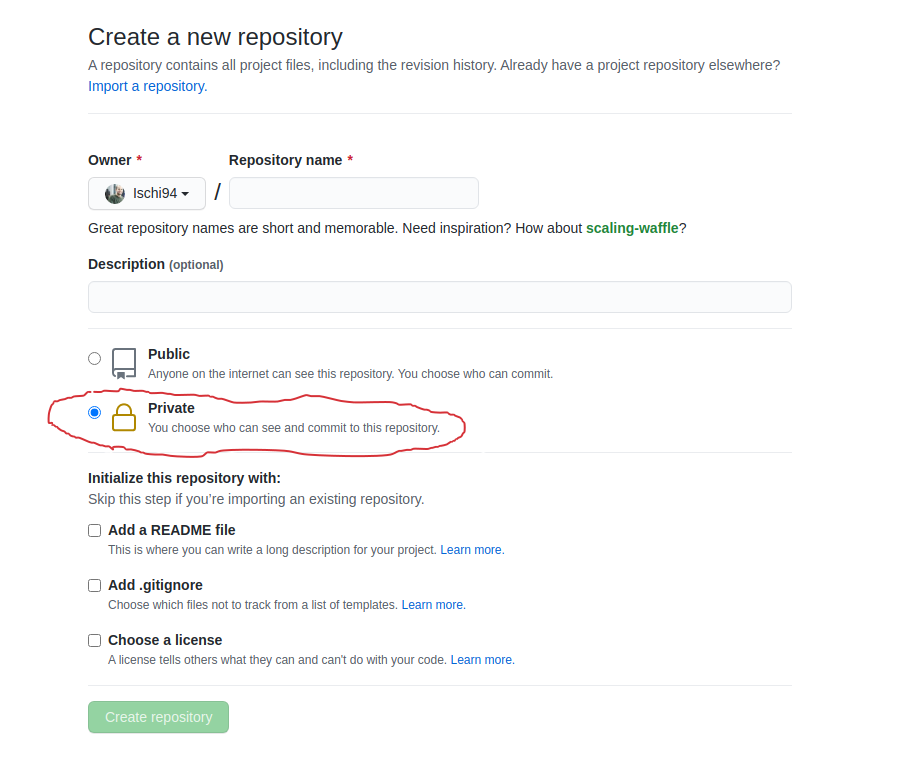
Fig. 2: Remember to set your repo on private
Now, wouldn’t it be sufficient to give only reviewers access to the repo? To do that, you would need to invite the reviewers as contributors, and for that you will need their names. Not really helpful for blind peer-review, though. So we do need another tool to do that. Here figshare.com really shines. Figshare will deposit a snapshot of our repo from github and generate a link. Anyone who has the link can access and download a repo with all the code and data in the same structure as in the original repo.
3 Generating a link
The first thing you need to do is to register on figshare. You can now store files there up to a total of 20 GB. The home screen will show you two buttons: Create a new item and the github logo.
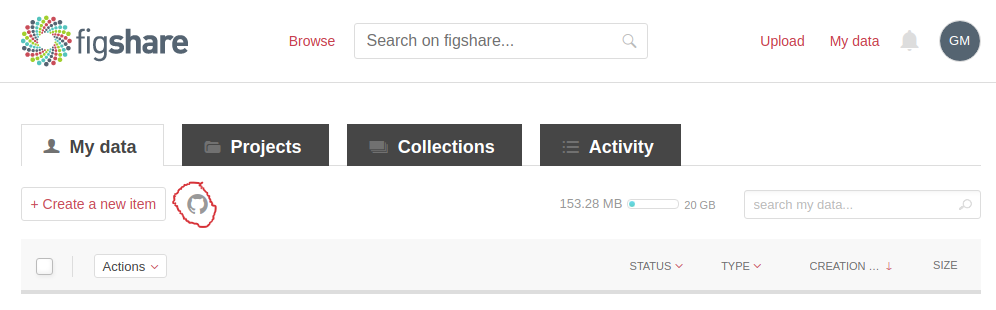
Fig. 3: Link your github account to figshare
By clicking on the github symbol, you can link your github account to figshare. You will also have access to your private repos.
After linking your github account to figshare, you can import any repositories (again by clicking on the github symbol). First you will be asked to select the repo and then you need to click on the import repository button on the lower right. Now close the window and you will see a new item on your figshare home screen. Click on it and the window of Fig.4 will open up.
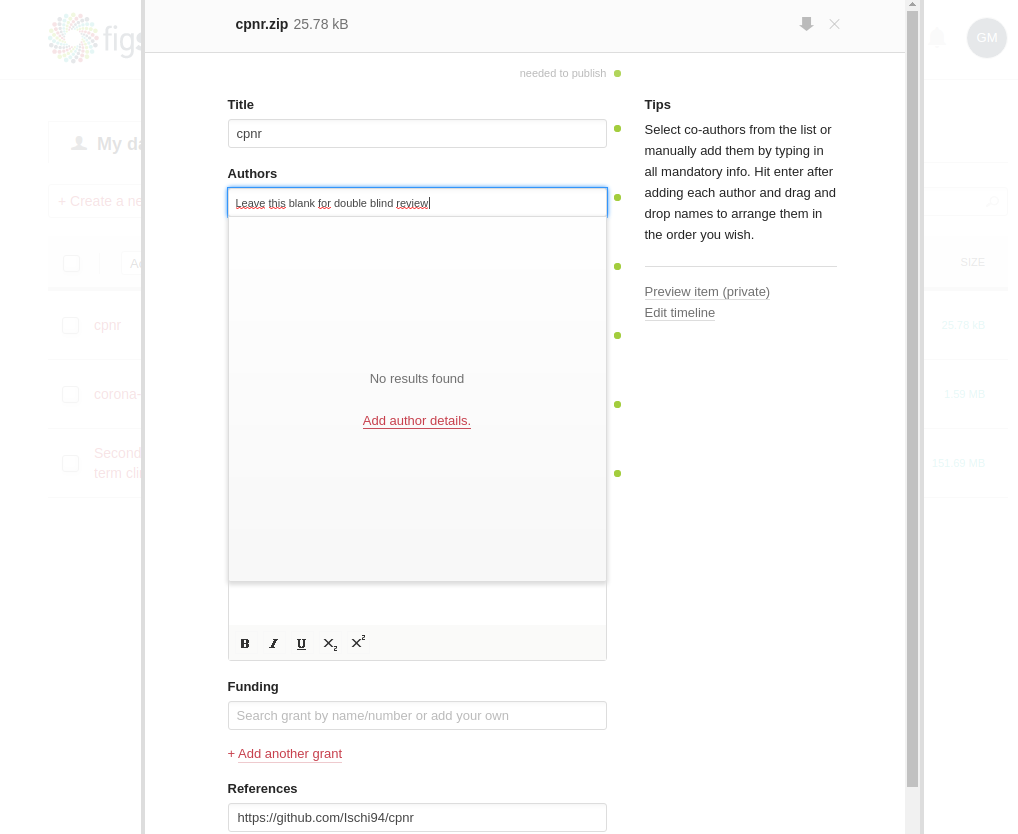
Fig. 4: Adjust figshare settings for your data
Here you can delete your name if you participate in double-blind peer-review. If you scroll down, you can add a description. If you were diligent previously, you can just copy the text from your github README there.
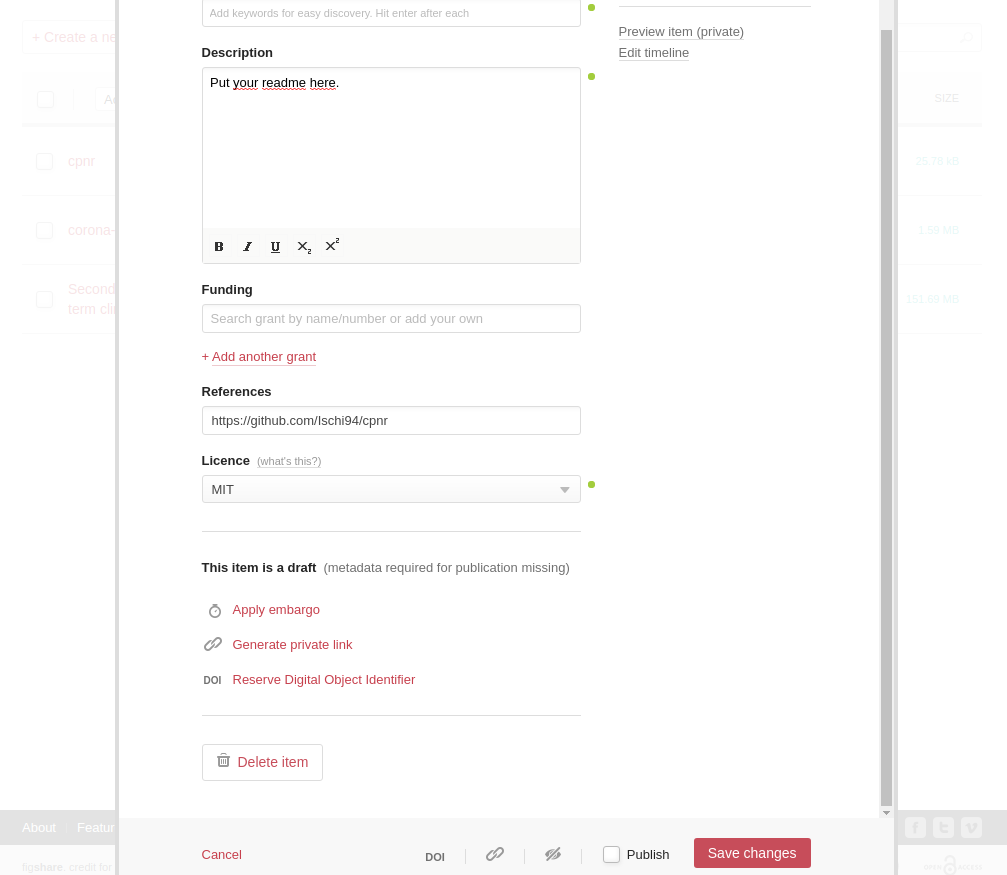
Fig. 5: Generate link
By clicking on generate private link you can (you guessed it) generate a private link. Copy this link and keep it save. You can put it in the cover letter to the editor during submission and he can then distribute the link to the reviewers. Now make sure to not flag the Publish option. This will make your data publicly available and we don’t want that, yet. Just save without publishing and you’re fine. Anyone who has the link can now access a zip file with the github repo. You are ready for submission.
Pro tip: If you release a new version of your github repo before cloning it to figshare, you will always be able to reference back to the version you were sending out to review, even if you have made changes to the repo. Just make sure to add “submission” to the flag to find it easily, e.g. v1.submission.
I hope this might help some of you to share your awesome research more easily.